
Cross-Industry Standard Process for Data Mining, or CRISP-DM, is an industry-proven process model provides an overview of the data mining life cycle. It is also a methodology that includes descriptions of the typical phases of a project, the tasks involved with each phase, and an explanation of the relationships between these tasks.
The life cycle model consists of six phases, with arrows indicating dependencies between phases. The sequence of the phases is not set in stone, a fact illustrated by the various depictions that can be found online. It is possible to move back and forth between phases as often as needed or skip phases altogether if they are not relevant. CRISP-DM allows you to create a data mining model that fits your needs.
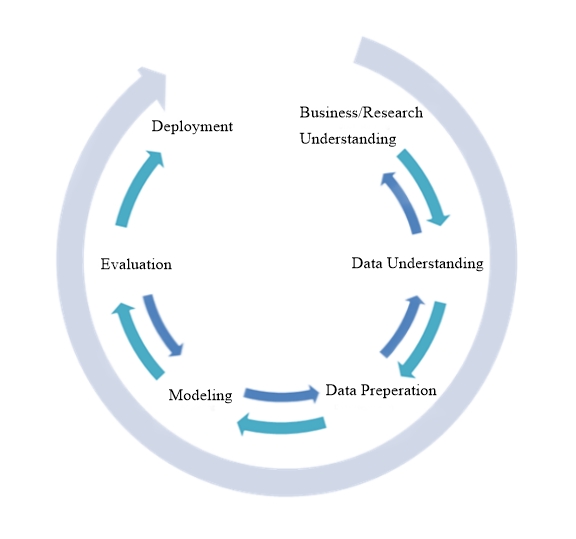
Business/Research Understanding Phase
The goal of the first phase is to come up with a proposed solution to a specific problem presented by the business. An investigation must be conducted to make sure there is a clear understanding of the objectives and requirements based on business goals, and not on any existing reports or processes. This should also consider existing resources and should involve any subject matter experts within the company. This specific business objective should then be converted into an equally clear data mining definition that communicates the goals that, if met, can be used by the business to address the original problem or question. This should include specifying the type of data problem being faced and the benchmarks to be used for measuring the technical goals and outcomes. With this information in hand, a project plan can be put in place which specifies the effort required, resources needed, and cost.
Data Understanding Phase
The data understanding phase of CRISP-DM begins with the initial data collection, followed by a close examination to familiarize yourself with the data collected. The goal here is to evaluate the quality of the data, identify potential problems, gain insights into the data, and potentially detect interesting subsets that may lead to actionable patterns. This step is critical in avoiding unexpected problems during the next phase–data preparation–which is typically the longest part of a project. It is possible that this might also require going back to the previous phase if the problem posed isn’t clear enough.
Data Preparation Phase
As stated, the data preparation is the most time-consuming part of data mining, taking an estimated 50-70% of the required time and effort, and is also the most important. It includes all the activities necessary to construct the final dataset out of the initial raw data collected in the previous phase, including case and variable selection, variable transformation, and data cleansing.
Modeling Phase
The modeling phase is where the hard work from the previous three phases begins to pay off. Sometimes requiring multiple passes using several different models, the process usually begins using default parameters that will be fine-tuned over time. It is also possible that, based on a models’ requirements, it will be necessary to loop back to the preparation phase to manipulate the data to fit a specific model better. In the end, the results should begin to shed some light on the business or research problem posed during Business Understanding.
Evaluation Phase
Now that most of the data mining has been completed, the models that have been built need to be tested using the business success criteria established at the beginning of the project to ensure both their quality and effectiveness and that all critical business issues have been sufficiently considered. Ultimately, one model should be chosen as the best choice to proceed with.
Deployment Phase
The deployment phase is where the new insights gained in the previous phase will be used to make changes within the organization. In general, this includes two activities: planning and monitoring the deployment of a code representation of the model and any completion tasks, such as reports and project reviews. The deployed code representation will be used to score or categorize new data as it arises that are then read into a data warehouse and to create a means for the use of that new data in the solution of the original business problem.

You must be logged in to post a comment.